
In order for you the advantages of a contemporary AI chatbot with out having to ship your information to the Web, it’s essential to run a big language mannequin in your PC.
Large language models (LLMs) are superior AI programs designed to know and generate textual content, code, and carry out a wide range of pure language processing duties. These instruments have remodeled the way in which we use computer systems, making duties like content material creation, coding and problem-solving a lot simpler.
Whereas cloud-based LLMs like ChatGPT and Claude are extensively used and among the best AI chatbots round, working these fashions immediately in your laptop comes with key advantages like higher privateness, extra management, and decrease prices. With native deployment, your information stays in your system, and also you don’t want an web connection or subscription charges to make use of the AI.
Able to get began? This information will stroll you thru the fundamentals of what LLMs are, why you may wish to run one regionally and the right way to set one up on Home windows and Mac, in as easy and easy a means as doable!
What’s a Massive Language Mannequin (LLM)?
A big language mannequin is a deep studying algorithm educated on huge quantities of textual content information to course of and generate pure language. These fashions use superior neural community architectures to know context, detect sentiment, and generate human-like responses throughout numerous functions.
LLMs can carry out a powerful vary of duties with out requiring further specialised coaching. They excel at understanding advanced queries and might generate coherent, contextually acceptable outputs in a number of codecs and languages.
The flexibility of LLMs extends past easy textual content processing. They’ll help with code technology, carry out language translation, analyze sentiment, and even assist with inventive writing duties. Their means to study from context makes them notably helpful for each private {and professional} use.
Why run an LLM regionally?
Operating LLMs regionally supplies enhanced privateness and safety, as delicate information by no means leaves your system. That is notably essential for companies dealing with confidential info or people involved about information privateness.
Native deployment provides considerably lowered latency in comparison with cloud-based options. With out the necessity to ship information forwards and backwards to distant servers, you may count on sooner response instances and extra dependable efficiency, particularly essential for real-time functions.
Value effectivity is one other main benefit of native LLM deployment. Whereas there could also be preliminary {hardware} investments, working fashions regionally will be extra economical in the long term in comparison with subscription-based cloud providers.
Key advantages of native LLM deployment embody:
- Full information privateness and management
- Decreased latency and sooner response instances
- No month-to-month subscription prices
- Offline performance
- Customization choices
- Enhanced safety
- Independence from cloud providers
Tips on how to run an LLM regionally on Home windows
Operating giant language fashions (LLMs) regionally on Home windows requires some particular {hardware}. Your PC ought to help AVX2 directions (most AMD and Intel CPUs launched since 2015 do, however test along with your CPU producer to make certain!) and have at the least 16GB of RAM.
For finest efficiency, you must also have a contemporary NVIDIA or AMD graphics card (just like the top-of-the-line Nvidia GeForce RTX 4090) with at the least 6GB of VRAM.
Thankfully, instruments like LM Studio, Ollama, and GPT4All make it easy to run LLMs on Home windows, providing easy-to-use interfaces and streamlined processes for downloading and utilizing open-source fashions.
LM Studio
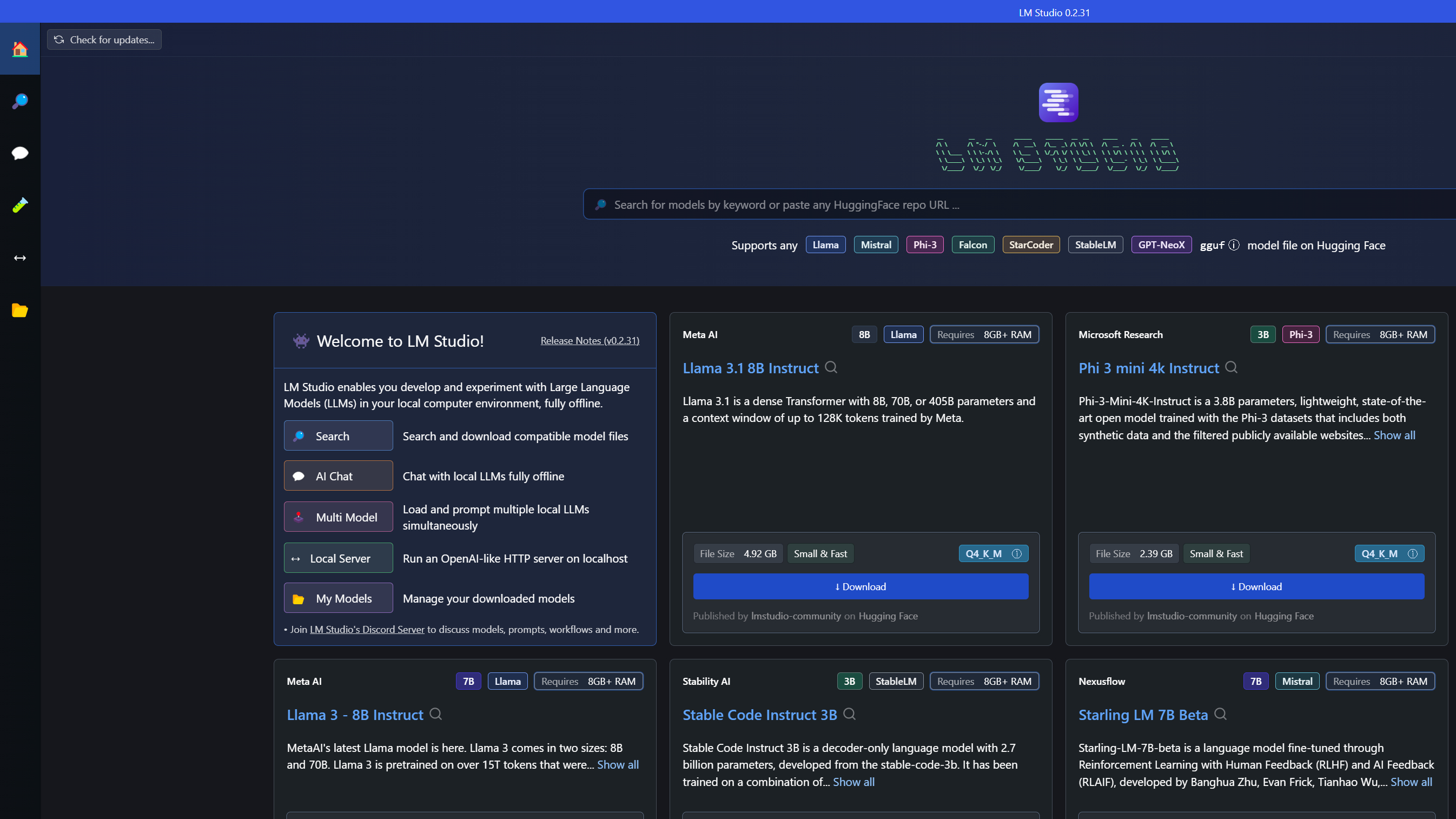
LM Studio is among the best instruments for working LLMs regionally on Home windows. Begin by downloading the LM Studio installer from their web site (round 400MB). As soon as put in, open the app and use the built-in mannequin browser to discover obtainable choices.
While you’ve chosen a mannequin, click on the magnifying glass icon to view particulars and obtain it. Remember the fact that mannequin recordsdata will be giant, so be sure you have sufficient storage and a steady web connection. After downloading, click on the speech bubble icon on the left to load the mannequin.
To enhance efficiency, allow GPU acceleration utilizing the toggle on the correct. This can considerably velocity up response instances in case your PC has a appropriate graphics card.
Ollama
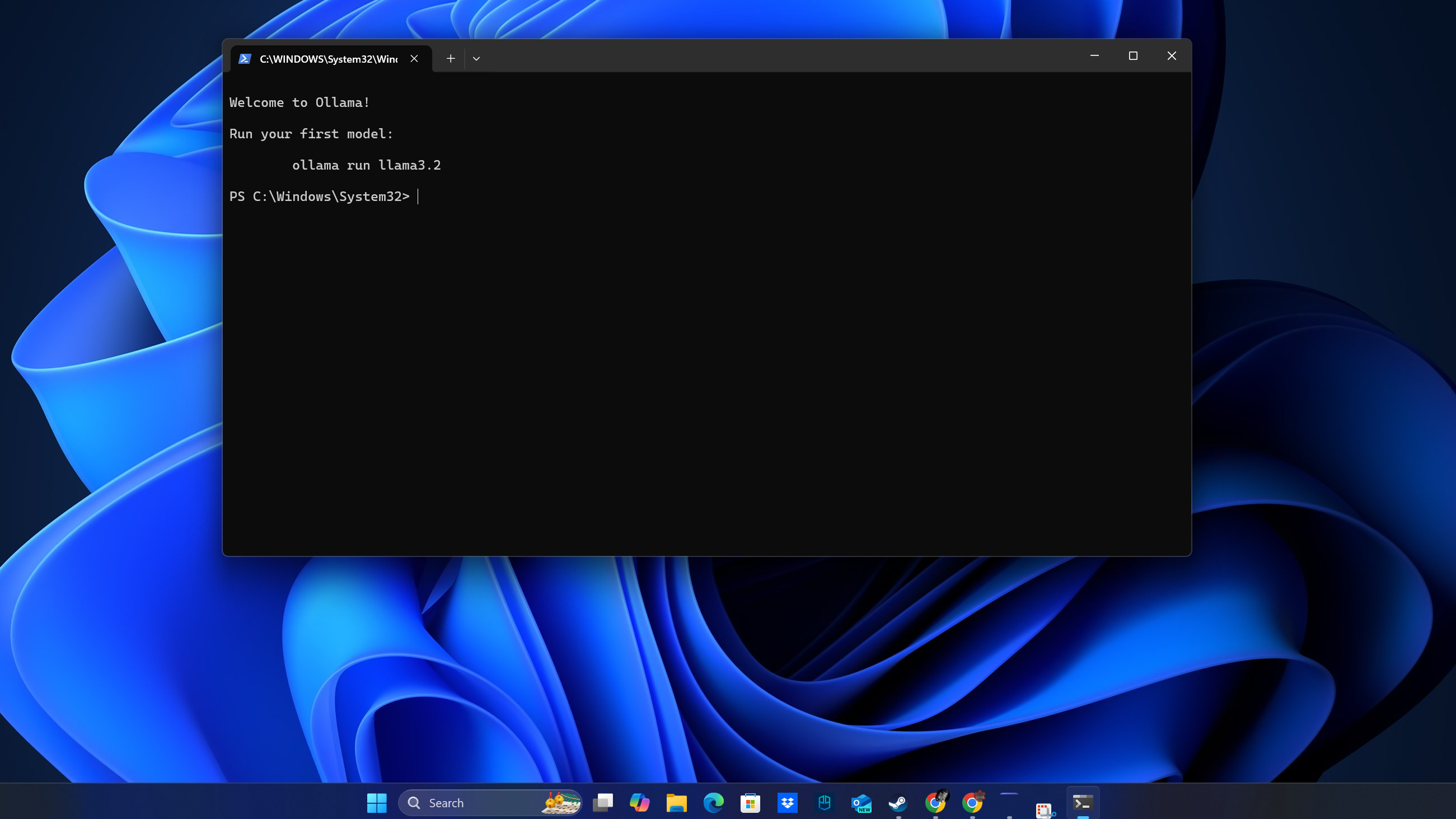
Ollama is one other glorious possibility for working LLMs regionally. Begin by downloading the Home windows installer from ollama.com. As soon as put in, Ollama runs as a background service, and you may work together with it through the command line.
To decide on a mannequin, go to the Fashions part on Ollama’s web site. Copy the command supplied to your chosen mannequin (e.g., “ollama run”) and paste it into your command immediate. The mannequin will robotically obtain and arrange for native use.
Ollama helps a number of fashions and makes managing them straightforward. You possibly can swap between fashions, replace them, and even run a number of cases in case your {hardware} can deal with it.
Tips on how to run an LLM regionally on macOS

Mac customers with Apple Silicon (M1/M2/M3) chips have nice choices for working language fashions (LLMs) regionally. The Neural Engine constructed into Apple Silicon is designed for environment friendly AI processing, making it well-suited for working these fashions while not having a devoted GPU.
When you’re utilizing a Mac with macOS 13.6 or newer, you may run native LLMs successfully with instruments optimized for the platform. The method can also be less complicated on Macs in comparison with Home windows, thanks to higher integration with AI instruments and the Unix-based system structure.
Homebrew

The best approach to get began on Mac is thru Homebrew. You possibly can obtain the Homebrew installer direct from the web site, or you may open Terminal (press Cmd + Area, kind “Terminal” and hit Enter) and set up the LLM package deal by working ‘brew set up llm’. This command units up the essential framework wanted to run native language fashions.
After set up, you may improve performance by including plugins for particular fashions. For instance, putting in the gpt4all plugin supplies entry to further native fashions from the GPT4All ecosystem. This modular strategy means that you can customise your setup based mostly in your wants.
LM Studio
LM Studio supplies a local Mac software optimized for Apple Silicon. Obtain the Mac model from the official web site and comply with the set up prompts. The applying is designed to take full benefit of the Neural Engine in M1/M2/M3 chips.
As soon as put in, launch LM Studio and use the mannequin browser to obtain your most well-liked language mannequin. The interface is intuitive and just like the Home windows model, however with optimizations for macOS. Allow {hardware} acceleration to leverage the complete potential of your Mac’s processing capabilities.
Closing ideas

Operating LLMs regionally requires cautious consideration of your {hardware} capabilities. For optimum efficiency, your system ought to have a processor supporting AVX2 directions, at the least 16GB of RAM, and ideally a GPU with 6GB+ VRAM.
Reminiscence is the first limiting issue when working LLMs regionally. An excellent rule of thumb is to double your obtainable reminiscence and subtract 30% for model-related information to find out the utmost parameters your system can deal with. For instance:
- 6GB VRAM helps fashions as much as 8B parameters
- 12GB VRAM helps fashions as much as 18B parameters
- 16GB VRAM helps fashions as much as 23B parameters
For Mac customers, Apple Silicon (M1/M2/M3) chips present glorious efficiency by way of their built-in Neural Engine, making them notably well-suited for working native LLMs. You will want macOS 13.6 or newer for optimum compatibility.
- Privateness necessities and information sensitivity
- Obtainable {hardware} sources
- Supposed use case (inference vs. coaching)
- Want for offline performance
- Value issues over time
For improvement functions, it is beneficial to make use of orchestration frameworks or routers like LlamaIndex or Langchain to handle your native LLM deployments. These instruments present helpful options for error detection, output formatting, and logging capabilities.
Now you recognize every part it’s essential to get began with putting in an LLM in your Home windows or Mac PC and working it regionally. Have enjoyable!
Extra from Tom’s Information
This articles is written by : Nermeen Nabil Khear Abdelmalak
All rights reserved to : USAGOLDMIES . www.usagoldmines.com
You can Enjoy surfing our website categories and read more content in many fields you may like .
Why USAGoldMines ?
USAGoldMines is a comprehensive website offering the latest in financial, crypto, and technical news. With specialized sections for each category, it provides readers with up-to-date market insights, investment trends, and technological advancements, making it a valuable resource for investors and enthusiasts in the fast-paced financial world.