
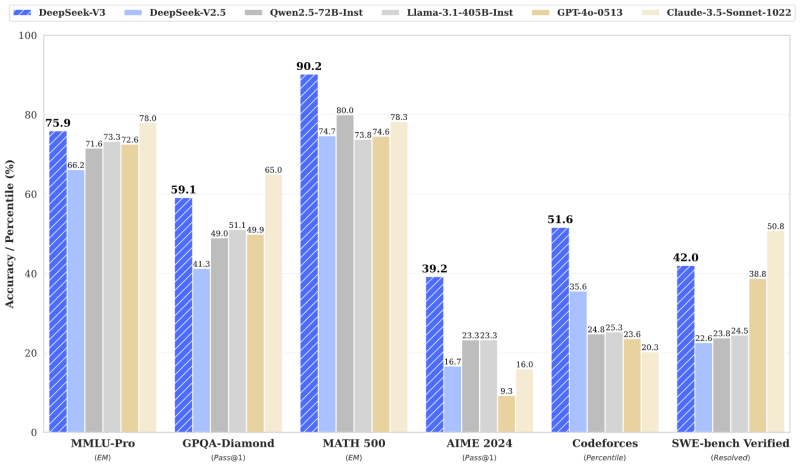
In the world of large language models (LLMs) there tend to be relatively few upsets ever since OpenAI barged onto the scene with its transformer-based GPT models a few years ago, yet now it seems that Chinese company DeepSeek has upended the status quo. Its new DeepSeek-V3 model is not only open source, it also claims to have been trained for only a fraction of the effort required by competing (open & closed source) models, while performing significantly better.
The full training of DeepSeek-V3’s 671B parameters is claimed to have only taken 2.788 hours on NVidia H800 (Hopper-based) GPUs, which is almost a factor of ten less than others. Naturally this has the LLM industry somewhat up in a mild panic, but for those who are not investors in LLM companies or NVidia can partake in this new OSS model that has been released under the MIT license, along with the DeepSeek-R1 reasoning model.
Both of these models can be run locally, using both AMD and NVidia GPUs, as well as using the online APIs. If these models do indeed perform as efficiently as claimed, they stand to massively reduce the hardware and power required to not only train but also query LLMs.
This articles is written by : Nermeen Nabil Khear Abdelmalak
All rights reserved to : USAGOLDMIES . www.usagoldmines.com
You can Enjoy surfing our website categories and read more content in many fields you may like .
Why USAGoldMines ?
USAGoldMines is a comprehensive website offering the latest in financial, crypto, and technical news. With specialized sections for each category, it provides readers with up-to-date market insights, investment trends, and technological advancements, making it a valuable resource for investors and enthusiasts in the fast-paced financial world.