
If you haven’t heard, Nvidia is investing $5 billion in Intel. According to Nvidia CEO Jensen Huang, this exciting Nvidia-Intel alliance will create “Intel x86 SoCs that integrate Nvidia GPU chiplets, fusing the world’s best CPU and GPU.” This could be the injection Intel needs to break out of its funk and course-correct its downward trajectory.
But this fusion isn’t just about, say, improving Intel’s Arc integrated graphics. It’s actually a step towards AI PC dominance. Nvidia GPUs have long been the best hardware for local AI workloads, but they’re limited by VRAM. With Intel’s help, Nvidia could finally solve that bottleneck—by developing the same power that Apple has been wielding.
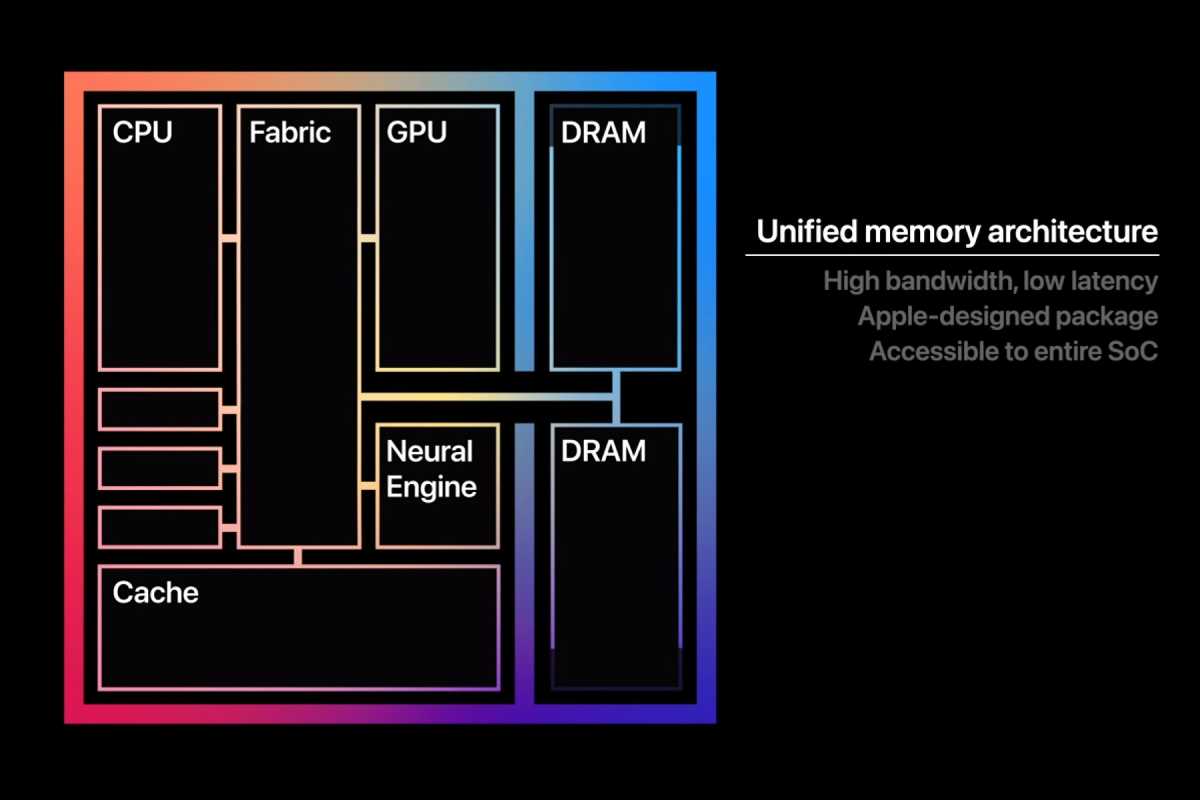
I’m talking about unified memory
Picture a modern desktop PC that’s fitted with an Intel CPU and Nvidia GPU. The Intel CPU relies on the RAM on the motherboard while the Nvidia GPU relies on the VRAM built into itself. To communicate, they need to move data between RAM and VRAM—and that’s slow.
For PC gaming, this isn’t a major problem. For example, an Nvidia GeForce RTX 5080 has 16GB of VRAM and that’s plenty for games. But for GPU compute tasks, VRAM is essentially the data workspace, so more VRAM is better. This is critical for local LLMs and other local AI tasks, but also for any CUDA workloads on Nvidia GPUs.
In other words: If you want to run a local LLM on your desktop, it has to fit into your GPU’s memory. Got a desktop PC with a whopping 128GB of RAM? It doesn’t matter. If your GPU only has 16GB of VRAM, that’s your limit—and that just isn’t enough for next-gen AI.

Foundry
Yes, Nvidia has the most mature GPU compute system and the fastest, most powerful GPUs in the world. But to take advantage of them for memory-hungry tasks, you need a lot of VRAM. At a certain point, it’s no longer about GPU speed—it’s about how many gigabytes of data you can fit into the GPU’s memory for direct, speedy access.
Enter unified memory. You can think of unified memory as a single pool of RAM that’s shared between CPU and GPU. With unified memory, communication between CPU and GPU is faster since data doesn’t need to be constantly moved from RAM to VRAM and vice versa. It also expands how much RAM the GPU has access to.
Now, let me be clear: Intel and Nvidia have NOT announced unified memory. Not yet, anyway. But they’ve announced something close: the integration of an Nvidia GPU chiplet on the same SoC package as an Intel CPU, connected with NVLink. And in its data center products, NVLink-C2C allows the CPU and GPU to share memory. Sound familiar?
AMD, Apple, and Qualcomm all have shared memory already
On the Mac side, Apple Silicon is the poster child for unified memory. You can buy a MacBook with 128GB of unified memory, and that memory can be used by both the MacBook’s CPU and GPU.
Meanwhile, an Nvidia GeForce RTX 5090 has 32GB of VRAM. For AI workloads where memory capacity is the bottleneck, a MacBook can outperform a beefy desktop PC with a high-end Intel CPU and an RTX 5090, even though Nvidia’s RTX GPU is much faster than Apple’s.
You also have AMD’s APU architecture (which offers system memory shared between CPU and GPU), Qualcomm’s Snapdragon X (which has unified memory like Apple), and Intel’s Lunar Lake platform (which has on-package memory shared between CPU and GPU).
Apple
AMD’s Ryzen AI Max+ supports up to a maximum of 128GB of memory, but many AI tools and GPU compute workloads are designed for CUDA, Nvidia’s software platform. Without CUDA, that AMD system may not be compatible with the tools you want to run. (And those integrated Qualcomm and Intel GPUs just aren’t that fast. Right now, only AMD and Apple are truly in the running.)
Though they have unified memory, Apple, AMD, Qualcomm, and Intel don’t have the powerful GPUs of Nvidia or the mature CUDA platform that makes Nvidia the standard for GPU compute tasks. Yet, while CUDA is the de facto standard, the industry is trying to change this with technologies like Windows ML. Competitors are chipping away at Nvidia’s lead here.
To pull ahead again, Nvidia needs to find a way for its GPUs to access a system’s main pool of memory—just like Apple, AMD, and Qualcomm already allow on their SoCs. It doesn’t really matter if Nvidia has the most powerful GPU compute solution if the AI models and data can’t fit into the VRAM of said solution.
Not official, but the hints are there
In Nvidia’s official announcement, the company says “Intel will build and offer to the market x86 system-on-chips (SOCs) that integrate Nvidia RTX GPU chiplets. These new x86 RTX SOCs will power a wide range of PCs that demand integration of world-class CPUs and GPUs.” And in Intel’s official announcement, the two will “focus on seamlessly connecting Nvidia and Intel architectures using Nvidia NVLink.”
So, yeah, there aren’t many details here, and neither Nvidia nor Intel are talking about memory. Will the memory be on the GPU itself? Well, Nvidia describes this as “a new class of integrated graphics.” At this point, all major SoCs with integrated graphics—from Apple, AMD, Qualcomm, and even Intel itself—use unified or pooled memory. (Some platforms have memory unified at the hardware level, while others just make it fast for the GPU to share access to the system’s RAM. The key is that the GPU isn’t only stuck with its own small amount of VRAM.)

Mattias Inghe / Foundry
Nvidia and Intel haven’t announced when they’ll ship hardware with this architecture, but multiple analysts expect 2027. This isn’t a one-off partnership, however, and it will continue. The first SoC package won’t be the last, and the architecture will likely evolve… and I believe it’ll move towards closer integration between Intel’s CPUs and Nvidia’s GPUs.
So, while Nvidia and Intel haven’t officially announced unified memory—in fact, they haven’t said anything about memory—it seems like a smart direction. All the talk about a “virtual giant SoC” where the CPU and GPU are “seamlessly connected” is a strong hint about where this is going, and NVLink is another big hint. In its data center products, Nvidia has a form of NVLink (called NVLink-C2C) that allows CPUs and GPUs to use the same pool of memory. (There’s no guarantee that’s what this will be, of course—especially in the first generation.)
Let me wear my informed speculation hat for a second: Nvidia and Intel would both love to deliver a unified memory architecture, but it’ll take multiple hardware generations to get there, and I’d bet Nvidia and Intel engineers are already talking about this as we speak. The first-generation product probably won’t be true unified memory—Intel and Nvidia would be hyping that up in their press releases if it were—but they’re almost certainly moving in that direction.
We’ll have to wait for more details, but Nvidia finally has a plausible path to crushing its competition in the AI PC wars. Nvidia already has the best GPU system; the only missing piece is memory. With Intel on board, Nvidia now has a roadmap to get where it needs to be. But Nvidia and Intel will need time to deliver the right product, and I expect that’s why they’re not talking about memory just yet. Stay tuned.
Subscribe to Chris Hoffman’s newsletter, The Windows Readme, for more expert PC advice from a real human.
This articles is written by : Nermeen Nabil Khear Abdelmalak
All rights reserved to : USAGOLDMIES . www.usagoldmines.com
You can Enjoy surfing our website categories and read more content in many fields you may like .
Why USAGoldMines ?
USAGoldMines is a comprehensive website offering the latest in financial, crypto, and technical news. With specialized sections for each category, it provides readers with up-to-date market insights, investment trends, and technological advancements, making it a valuable resource for investors and enthusiasts in the fast-paced financial world.