

The world of software has seen many paradigms come and go, all of which were supposed to revolutionize its development. Still, one of the basic tenets in engineering of there being no shortcuts to just doing the work properly also rings true in the field of software engineering: trying to skip ‘nice to haves’ like proper documentation, code formatting, and proper testing inevitably results in developers nervously trying to ignore the looming avalanche of technical and other project debts as they keep piling up.
While Test-Driven Development (TDD) once got praised as the silver bullet, the principle of writing tests before writing code merely postpones the inevitable project collapse. The elephant in the room is that you cannot pass on the basics in engineering and expect to come out fine on the other end. There’s a reason why phrases like “all tests green, successfully failed in production” have become common.
This is where the concept of Comment-Driven Development (CDD) comes into play. What started as a bit of a joke many years ago stuck in my mind and led me to my current approach in software development that tries to effectively mirror solid engineering principles.
Defining Comments
In the field of software engineering, code comments are often regarded as a bit of an unloved stepchild. No developer regards them in the same way, few appreciate them, most neglect them and some outright banish them from their lives. The most extreme response here is probably that of the Clean Code movement, who together with the Self-Documenting Code crowd insist that inline comments in particular are unnecessary, an eyesore and that beautiful, well-written code documents itself.
Then there are those who use comments as a (temporary) crutch, as in what is referred to as ‘comment programming‘. This puts comments in the place where code is supposed to go, for either later replacement or to elucidate a specific aspect. None of this uses comments consistently to provide a parallel flow with the code that explains the what, why and how of said code.
Why this matters is that despite claims to the contrary, reading and understanding code is hard. Grasping architectural decisions and intuitively separating them from quick hacks is hard even if you’re reading back your own code after a few development cycles. This is also basically why writing documentation based on just code with at most spotty inline commentary is a nightmare at best.
After working with a variety of (commercial) codebases over the years that were practically dripping technical debt and regrets – as well as writing comprehensive documentation for some of them – I have become convinced that comments are ultimately the Alpha and Omega of a healthy codebase and up to date documentation.
Software Engineering

Although most people see the finished product of engineering and believe that that’s all there’s to it, the truth is that before that bridge, high-rise building or even some fancy electronic widget sees the light of day, most of the work has already happened. Building it is then theoretically as easy as following the provided instructions.
An essential point here is the assumption that said instructions are half-way correct and you don’t end up building your very own Millennium Tower.
Thus the process of engineering begins with the list of requirements. These have to be chiseled into the hardest of stone, as any change here will have potentially massive repercussions. From these requirements you can then begin to work on a design document that details the overall design of the product, from which the desired architecture follows.
While the specific details will differ for each specific field of engineering, it is this condensing from an abstract idea into increasingly more concrete steps that enables for all angles to be considered before committing to a specific decision that can be hard to revert or change later. In the case of the aforementioned Millennium Tower project, those in charge omitted steps like peer review, where an external set of eyes is asked to give their two cents, because this would have ‘taken too long’.
From Design To Code
Even if in general software is easier to change than e.g. the blueprints for a civil engineering project, you still want to avoid having to go back repeatedly to change or modify parts of a codebase. To this end you do not want to write code until you are very confident that said code is proper and correct.
Fortunately, with the detailed design document and architectural planning already in the bag you can then start start the feedback loop of laying out the foundations, with any obvious issues discovered during this phase being used to improve the design and architectural documentation.
Laying out these foundations involves creating the codebase’s basic layout, including details like creating header and source files with appropriate naming. Next, within these files the architectural structure is laid out, such as creating the skeletons of types, classes, functions and methods that establish the APIs.
For each file a heading comment block is added that briefly summarizes the file’s purpose, the features contained therein, as well as a truncated change list with date and name, for accountability.
At this point we are ready to pour in the details of each compile unit’s implementation, starting by taking the design and related documents and turning the details contained therein into comments that describe the overarching design decisions, special considerations, the flow within a section and any interactions with other modules.
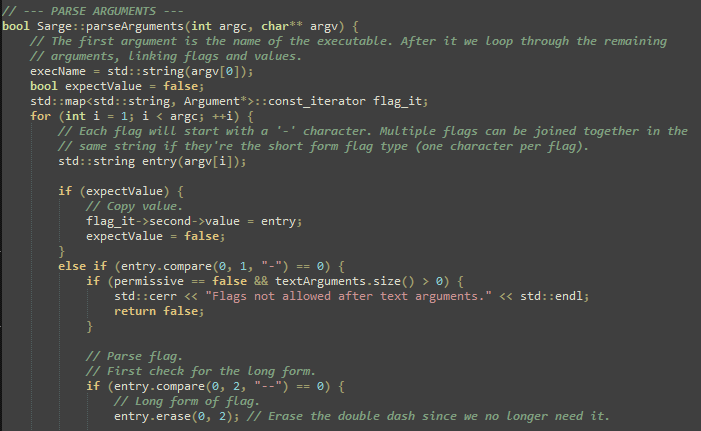
An example of this can be found in my Sarge command line argument parsing library, which both in its C++ and Ada form would be a very hairy mess of logic to keep track of without having the continuous flow of thought describing what is happening, why it’s happening and relevant implications.
Although it may seem simple and obvious, doing this consistently and in a way that doesn’t leave future you staring dumbfounded at a section of code, or chasing red herrings during a debugging session due to a flawed assumption is somewhat of an art. Here it’s crucial that whenever you find yourself in such a state that the relevant inline comments are updated or new ones added as necessary to prevent future confusion.
It shouldn’t even have to be said that keeping these comments – and related documentation – updated whenever code changes are made is absolutely paramount as well. While it’s ‘boring’ work, you don’t do it for your present self, but your future self and/or fellow developers who’ll otherwise use extremely colorful language related to your person.
Documentation And Tests
Writing the documentation with CDD starts from the first list of requirements, with the design document being the next major part, both providing the higher-level overview of the project before diving into the nitty-gritty of the architecture and implementation.
What the best approach here is largely depends on the project and who might be interested in documentation and to which extent. For a typical commercial project where there never is budget for ‘writing documentation’, simply having the design document and the detailed inline comments in the source might be what one has to settle for.
Here it might also be possible to use said inline comments to generate e.g. API listings from with tools such as Doxygen. My own experiences with such tools are mixed, but in a CDD context such auto-generated documentation could be significantly more useful, not to mention accurate.
Finally, any tests required to test specific functionality would be defined along with the code’s architecture, letting it define the testing scope rather than vice versa. With APIs for modules already settled early on, writing unit- and integration tests tends to be a lot easier and without the nagging and nebulous goal of that mystical ‘100% test coverage’.
Mitigating Circumstances
Of course, not every software project is the same, especially for hobbyist projects where you’re often the sole maintainer. It is here your prerogative to take all the shortcuts you want, as long as it is in the knowledge that you’ll only have yourself to blame.
This is why some of my projects are definitely a bit more loose in their adherence to CDD, while others are a complete stickler. for example, when I created my NyanSD network service discovery protocol, I started by writing out a complete requirements and design document, including the protocol itself. By following the top-down CDD approach here I was able to design and implement the entire protocol in the course of about two days, and have it mostly work first try.
Ultimately, CDD in my eyes is the correct approach to software engineering, as it saves a lot of time while being the only approach that actually follows basic engineering principles. You can change the field, but ultimately both physics and underlying hardware remain just as unimpressed by your personal views on how things ought to work.
This articles is written by : Nermeen Nabil Khear Abdelmalak
All rights reserved to : USAGOLDMIES . www.usagoldmines.com
You can Enjoy surfing our website categories and read more content in many fields you may like .
Why USAGoldMines ?
USAGoldMines is a comprehensive website offering the latest in financial, crypto, and technical news. With specialized sections for each category, it provides readers with up-to-date market insights, investment trends, and technological advancements, making it a valuable resource for investors and enthusiasts in the fast-paced financial world.